
Published on
April 22, 2026
~
5
min
-20260406-135938.png)




A pricing mismatch, a missing spec, an outdated product image…Most commerce errors don’t start where you think they do.
They don’t begin at checkout. They don’t begin in the frontend.
They begin much earlier, in product data.
When product information is scattered across systems, managed by different teams, and updated without control, errors become inevitable.
And once they appear, they don’t stay contained. They spread across every channel, every partner, and every customer touchpoint.
If most commerce errors originate from product data, then fixing the experience without fixing the data is solving the wrong problem.
Let’s look into why your product data is the true architect of your customer experience, and how to transition from scattered spreadsheets to a single, unified source of truth.
Product data fragmentation is not just about where data lives; it’s about how it behaves.
Each system stores product information differently.
Over time, these differences create misalignment, not just duplication. The same product starts to evolve in parallel across systems.
One version is updated with new pricing. → Another reflects outdated specifications. → A third includes missing attributes altogether.
Because these systems are not fully synchronised or governed by a central structure, inconsistencies are not immediately visible, but they are always present.
This is where the real risk begins.
What appears to be a single product is, in reality, multiple versions competing for accuracy across the ecosystem. And without a controlled layer to unify and validate this data, the system doesn’t fail because of one mistake; it fails because inconsistency is allowed to scale.
In modern digital commerce, product data is continuously distributed across multiple systems and channels. Once an error enters the flow, it doesn’t stay isolated; it gets replicated, synced, and published everywhere the product exists.
This is where the domino effect begins.
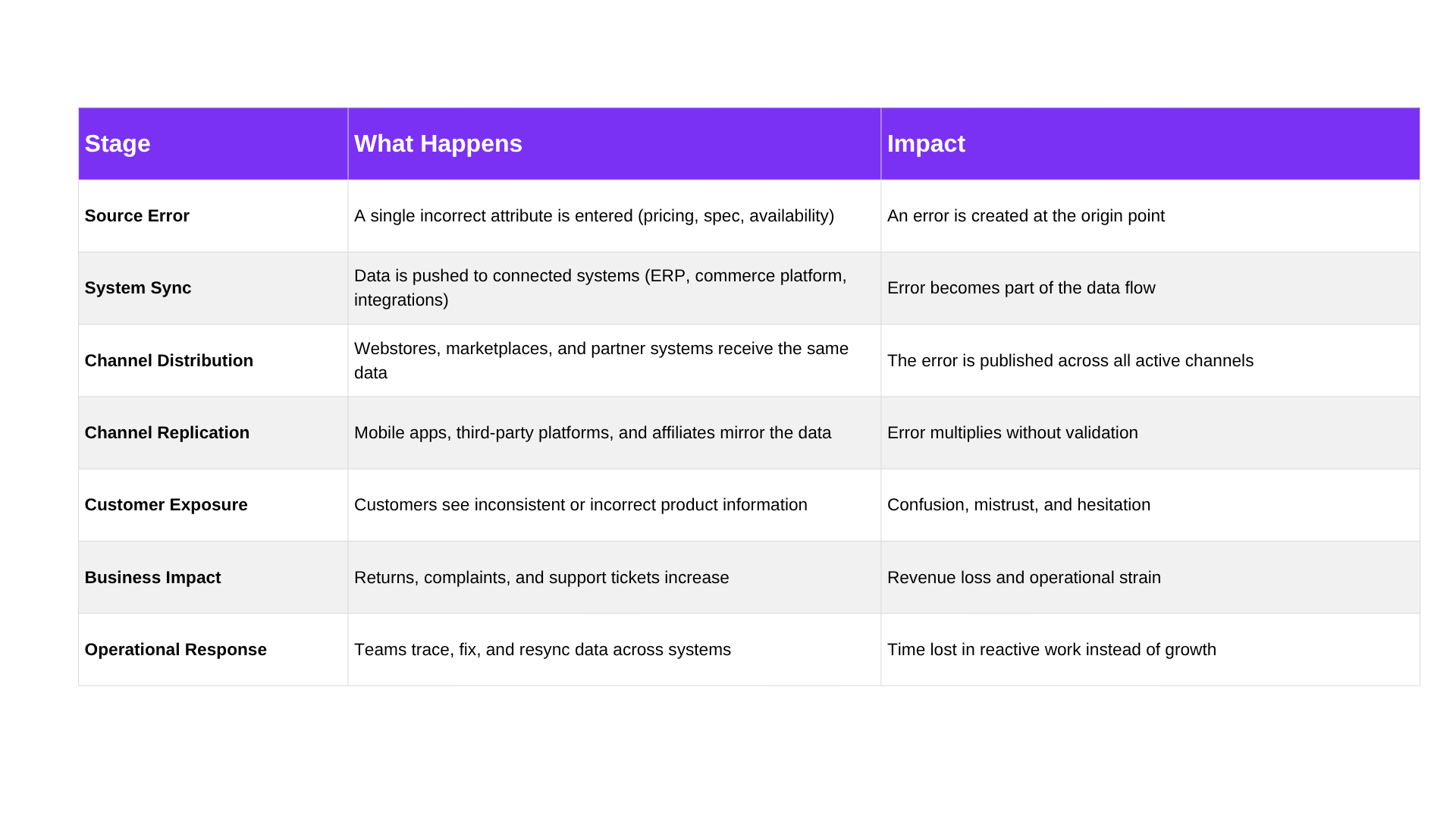
The issue is no longer a single mistake; it’s a chain reaction.
By the time the error is detected, it has already moved across multiple systems and touchpoints. Fixing it means retracing its path, correcting it everywhere, and ensuring every channel is updated again.
The more channels you operate, the faster this domino effect accelerates and the harder it becomes to control.
Most traditional systems were not designed to manage product data quality actively. They store information, transfer it, and display it, but they don’t question it. Once data enters the system, it is treated as valid by default, regardless of whether it is complete, consistent, or correct.
This creates a passive environment where errors are not stopped, only discovered after they have already caused impact.
Structure plays a big role here.
Many legacy systems rely on rigid data models that are difficult to adapt as product complexity grows. Adding new attributes, updating formats, or aligning data across regions often requires manual intervention or technical workarounds. As a result, teams delay updates or apply quick fixes instead of maintaining consistency at scale.
At the same time, ownership of product data is often unclear.
Different teams contribute to the same dataset, but without defined governance, validation rules, or approval workflows, there is no mechanism to ensure alignment before data is published. What gets entered is what gets distributed.
Synchronisation adds another layer of risk.
Updates across systems are rarely instantaneous or fully aligned, creating timing gaps in which outdated or partial information continues to circulate. Even when corrections are made, they may not propagate consistently across all endpoints.
Traditional systems are broken; they fail because they are not designed to prevent inconsistency at the source. They move data efficiently, but they don’t control it.
Once product data is treated as a governed asset rather than a scattered input, the entire structure of digital commerce changes.
Instead of reacting to errors after they spread, a Product Information Management (PIM) system prevents them from entering the system in the first place.
This shift happens across three core layers: how data is structured, how it is enriched, and how it is controlled.
A PIM system consolidates product data from multiple sources into a single, unified environment. ERP inputs, supplier feeds, internal databases, and regional updates all feed into one structured layer.
This eliminates duplicate product records and ensures every team works from the same dataset.
Instead of reconciling differences across systems, organisations operate from a single source of truth that defines how product information exists across the entire ecosystem.
Beyond centralisation, a PIM system standardises how product data is defined and enhanced.
Attributes are structured rather than free-form, ensuring consistency across categories and regions. Product descriptions, specifications, and media assets are enriched within a controlled framework, reducing variation and ambiguity.
This means the same product is not reinterpreted differently across channels; it is defined once, and consistently extended where needed.
The final layer is control.
PIM systems introduce validation rules, approval workflows, and role-based permissions that ensure product data is reviewed before it is published.
Incomplete, inconsistent, or non-compliant data is flagged early, preventing it from entering downstream systems.
This turns product data into a managed lifecycle rather than an uncontrolled flow.
This is where Lidia Commerce brings structure into execution.
Lidia PIM is built to operationalise exactly these principles (centralisation, enrichment, and governance) within a single, scalable system.
It helps teams unify fragmented product data, enhance it with structured attributes and rich content, and apply rule-based validation before anything is published.
Instead of fixing errors after they spread, Lidia ensures they are prevented at the source, giving organisations a controlled foundation for scalable, consistent digital commerce.
Commerce errors don’t start where they are seen; they start where product data is defined.
When product data is fragmented or loosely governed, inconsistencies scale across every system and channel. Fixing issues downstream only addresses the outcome, not the cause.
A structured PIM approach changes this by controlling product data at the source where it is created, enriched, and validated before distribution.
Instead of correcting errors after they spread, consistency is built in from the start.
Next Generation of Commerce | Lidia Commerce



